
Harvest CROO partnered with Ramblr to train their autonomous strawberry harvesters using the Ramblr Data Engine. By automating the ingestion, organization, and annotation of large-scale multimodal video data across 16 harvesters, Harvest CROO reduced annotation overhead, accelerated training cycles, and built a scalable data foundation for smarter, more accurate picking decisions – in one of the most dynamic environments in autonomous robotics.
The Challenge
For autonomous systems operating in unstructured environments, the data pipeline is often the bottleneck.
Teaching a robot to make real-world decisions requires data – massive amounts of it – continuously updated and precisely labeled. Harvest CROO's 16 robotic harvesters scan every berry on every plant across constantly changing strawberry fields – making picking decisions in real time, every 2 to 4 days. Each harvester generates continuous multimodal video streams from multiple cameras. Without a structured way to manage, process, and annotate that data at scale, training smarter models becomes slow, expensive, and inconsistent.
-
Continuous, high-volume video data generated across 16 autonomous harvesters
-
Multiple camera angles per harvester producing large-scale multimodal datasets
-
Unstructured data difficult to manage, organize, and annotate efficiently at scale
-
Annotation bottlenecks slow model training and limit the ability to handle edge cases
-
Dynamic field conditions requiring models that improve continuously, not just once
The Approach
Ramblr's Data Engine turns raw, unstructured video data into a structured, high-quality training foundation – automatically.
Video streams from every harvester and every camera angle are ingested and organized automatically, eliminating the manual overhead of handling large-scale multimodal datasets. Granular per-frame attributes and object relationships are annotated with precision – customized to the specific needs of Harvest CROO's picking models.
Active learning automates a significant portion of the annotation pipeline while preserving human oversight exactly where it matters: edge cases, accuracy verification, and ground-truth validation. The result is a continuously improving data engine that gets smarter with every harvest.
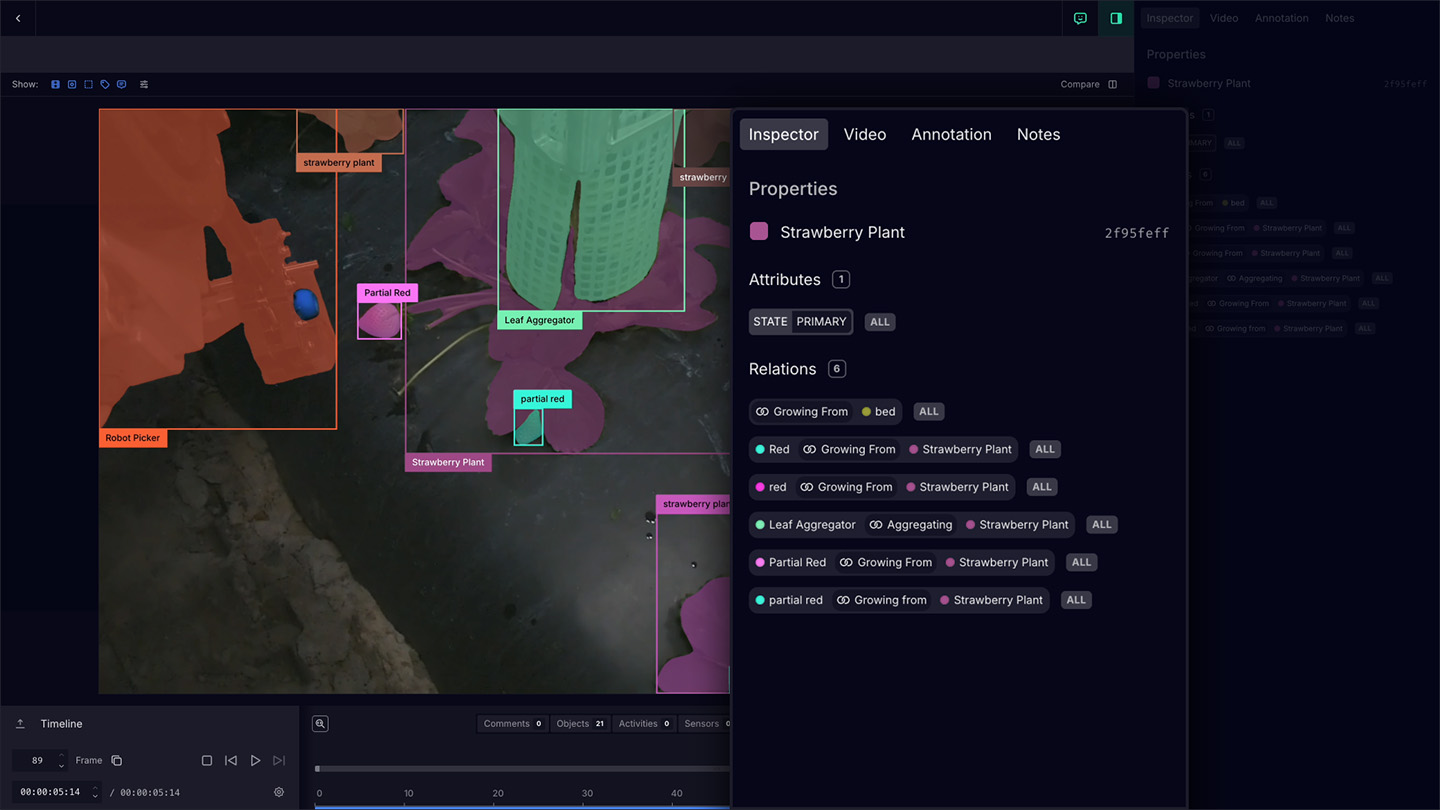
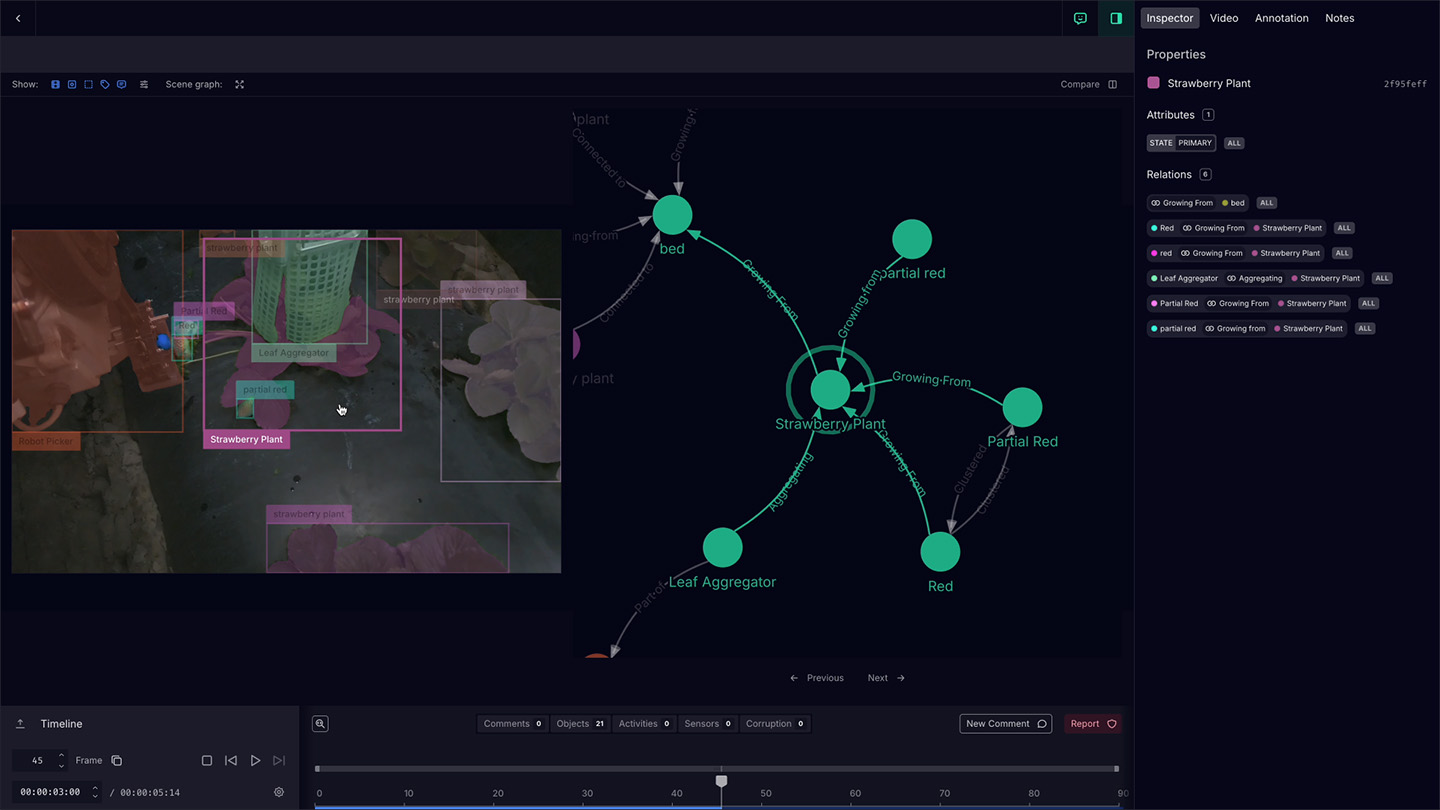
The Result
The gap between raw video and production-ready models is where most robotics teams lose time. The Ramblr Data Engine closes it.
With the Ramblr Data Engine, Harvest CROO replaced an annotation-heavy, bottleneck-prone pipeline with a scalable, automated training infrastructure – freeing their team to focus on model quality, not data management.
Testimonial
“With Ramblr's labeling platform, we reduced the overhead of multiple annotators to one while ensuring high-quality, advanced annotation. Customized workflows and active learning automated a significant portion of the process while allowing us to refine edge cases, verify accuracy, and ground-truth with ease.”
Joel Meine – Sr. UX/CX Designer and Strategist, Harvest CROO
Press and Media
Ramblr and Harvest CROO teach robotic harvesters to when to pick
Transform. Understand. Act.
Your knowledge base is already there. Ramblr AI Agents make it work. Are you ready to turn your product expertise into always-on AI guidance?